Hypothesis: Two-tailed test\[ H_0:p_1 = p_2 \]\[H_1: p_1 \neq p_2 \] - \(p_1\) the probability that a randomly selected obs from the population 1 will be in class 1. - \(p_2\) the probability that a randomly selected obs from the population 2 will be in class 1.
Decision: If p_value < \(\alpha\) then REJECT \(H_0\)
Hypothesis: Lower-tailed test\[ H_0:p_1 = p_2 \]\[H_1: p_1 < p_2 \] - \(p_1\) the probability that a randomly selected obs from the population 1 will be in class 1.
P-value\(= P( T \leq T_{Obs})\)
Decision: If p_value < \(\alpha\) then REJECT \(H_0\)
Hypothesis: Upper-tailed test\[ H_0:p_1 = p_2 \]\[H_1: p_1 > p_2 \] - \(p_1\) the probability that a randomly selected obs from the population 1 will be in class 1.
P-value\(= P( T \geq T_{Obs})\)
Decision: If p_value < \(\alpha\) then REJECT \(H_0\)
Chi-squared Test - Example 1
The number of items in two car loads.
Data
Defective
Non defective
Totals
Carload 1
a =13
b=73
\(n_1\) = 86
Carload 2
c = 17
d=57
\(n_2\) = 74
Totals
\(c_1\) = 30
\(c_2\)= 130
N = 160
2 x 2 contingency table
Question: Test whether there are differences in proportions of defective items between the two carloads.
Define the null and alternative hypotheses Answer:\[ H_0: p_1 = p_2 \]\[H_1: p_1 \neq p_2 \] This is an two-tailed test.
Find the Test statistic observed and null distribution Answer:\(T_{obs}=-1.2695\) and \(T\sim N(0,1)\)
Hypothesis: Two-tailed test\[ H_0:p_1 = p_2 \]\[H_1: p_1 \neq p_2 \] - \(p_1\) the probability that a randomly selected obs from the row 1 will be in col 1.
Decision: IF p_value < \(\alpha\) then REJECT \(H_0\)
Fisher’s Exact Test
Hypothesis: Lower-tailed test\[ H_0:p_1 = p_2 \]\[H_1: p_1 < p_2 \] - \(p_1\) the probability that a randomly selected obs from the row 1 will be in col 1.
P-value\(= P( T \leq T_{Obs})\)
Decision: IF p_value < \(\alpha\) then REJECT \(H_0\)
Hypothesis: Upper-tailed test\[ H_0:p_1 = p_2 \]\[H_1: p_1 > p_2 \] - \(p_1\) the probability that a randomly selected obs from the row 1 will be in col 1.
P-value\(= P( T \geq T_{Obs})\)
Decision: IF p_value < \(\alpha\) then REJECT \(H_0\)
Fisher’s Exact Test - Example
14 newly hired business majors. - 10 males and 4 females - 2 Jobs are needed: 10 Tellers and 4 Account Rep.
Data
Account Rep.
Tellers
Totals
Males
X=1
9
r = 10
Females
3
1
4
Totals
c= 4
10
N = 14
2 x 2 contingency table
Question: Test if females are more likely than males to get the account Rep. job.
Fisher’s Exact Test - Example
Define the null and alternative hypotheses Answer:\[ H_0: p_1 \geq p_2 \]\[H_1: p_1 < p_2 \] This is an lower-tailed test.
Find the Test statistic observed and null distribution Answer:\(T_{obs}=X=1\) and \(T\sim hypergeometric(14,10,4)\)`
Find P-value Answer: p-value=0.040959
Decision and Interpretation Answer: Since P-value < 0.05 then Reject \(H_0\).
Fisher’s Exact Test - Example with R
data =cbind(c(1,3),c(9,1)) # create datafisher.test(data,alternative ="l")
Fisher's Exact Test for Count Data
data: data
p-value = 0.04096
alternative hypothesis: true odds ratio is less than 1
95 percent confidence interval:
0.000000 0.897734
sample estimates:
odds ratio
0.05545513
Interpretation: Reject \(H_0\). There is evidence to support that the data is compatible with the assumption that females are more likely than males to get the account Rep. job.
Mantel-Haenszel Test 2x2xk
An extension of Fisher’s exact to several 2x2 tables.
, , Group 1
Success Failure
Treat. 10 1
Control 12 1
, , Group2
Success Failure
Treat. 9 0
Control 11 1
, , Group 3
Success Failure
Treat. 8 0
Control 7 3
mantelhaen.test(mydata,alternative ="g")
Mantel-Haenszel chi-squared test with continuity correction
data: mydata
Mantel-Haenszel X-squared = 1.0114, df = 1, p-value = 0.1573
alternative hypothesis: true common odds ratio is greater than 1
95 percent confidence interval:
0.7087777 Inf
sample estimates:
common odds ratio
4.357143
Chi-squared test rxc Table Difference in Probabilities
M =rbind("PrivateS"=c(6,14,17,9), "PublicS"=c(30,32,17,3))M
Pearson's Chi-squared test
data: M
X-squared = 1.5242, df = 3, p-value = 0.6767
The conclusion is that the college in which a student is enrolled is independent of whether high school training was in state or out of state
The Median Test
Test for equal medians.
\[H_0: \text{All C populations have the same median} \]\[H_1: \text{At least two populations have different medians} \]
Data
C random samples are independent
Arrange the data as follows:
Find the Grand Median (GM), that is the median of the combined samples.
Set up a 2 by C contingency table as follows:
Sample 1
Sample 2
…
Sample C
Totals
\(>\) GM
\(O_{11}\)
\(O_{12}\)
…
\(O_{1C}\)
a
\(\leq\) GM
\(O_{21}\)
\(O_{22}\)
…
\(O_{2C}\)
b
Totals
\(n_{1}\)
\(n_{1}\)
…
\(n_{C}\)
N
Test Statistic
\[ T = \frac{N^2}{ab} \sum_{i=1}^{C} \frac{O^2_{1i}}{n_i} - \frac{Na}{b} \]
Under Null hypothesis: \(T \sim \chi^2_{C-1}\); a chi-square distribution with C-1 degrees of freedom.
P-value\(=P(T \geq T_{obs})\)
Decision: IF p_value < \(\alpha\) then REJECT \(H_0\)
The Median Test - Example
4 methods of growing corn is used.
The yield per acre is measured and compared across the 4 methods.
Question: Do the medians yield per acre differ across the 4 methods.
Define the null and alternative hypotheses \[H_0: \text{All methods have the same median yield per acre} \]\[H_1: \text{At least two of the methods medians differ} \]
Set up data: See lecture notes
Test statistic:
\[T_{obs} = 17.6\]
Under Null hypothesis: \(T \sim \chi^2_{3}\)
The Median Test - Example R
# install.packages("agricolae")library(agricolae) # packagedata(corn) # data# The Median Testmedian_test_out=Median.test(corn$observation,corn$method)
The Median Test for corn$observation ~ corn$method
Chi Square = 17.54306 DF = 3 P.Value 0.00054637
Median = 89
Median r Min Max Q25 Q75
1 91.0 9 83 96 89.00 92.00
2 86.0 10 81 91 83.25 89.75
3 95.0 7 91 101 93.50 98.00
4 80.5 8 77 82 78.75 81.00
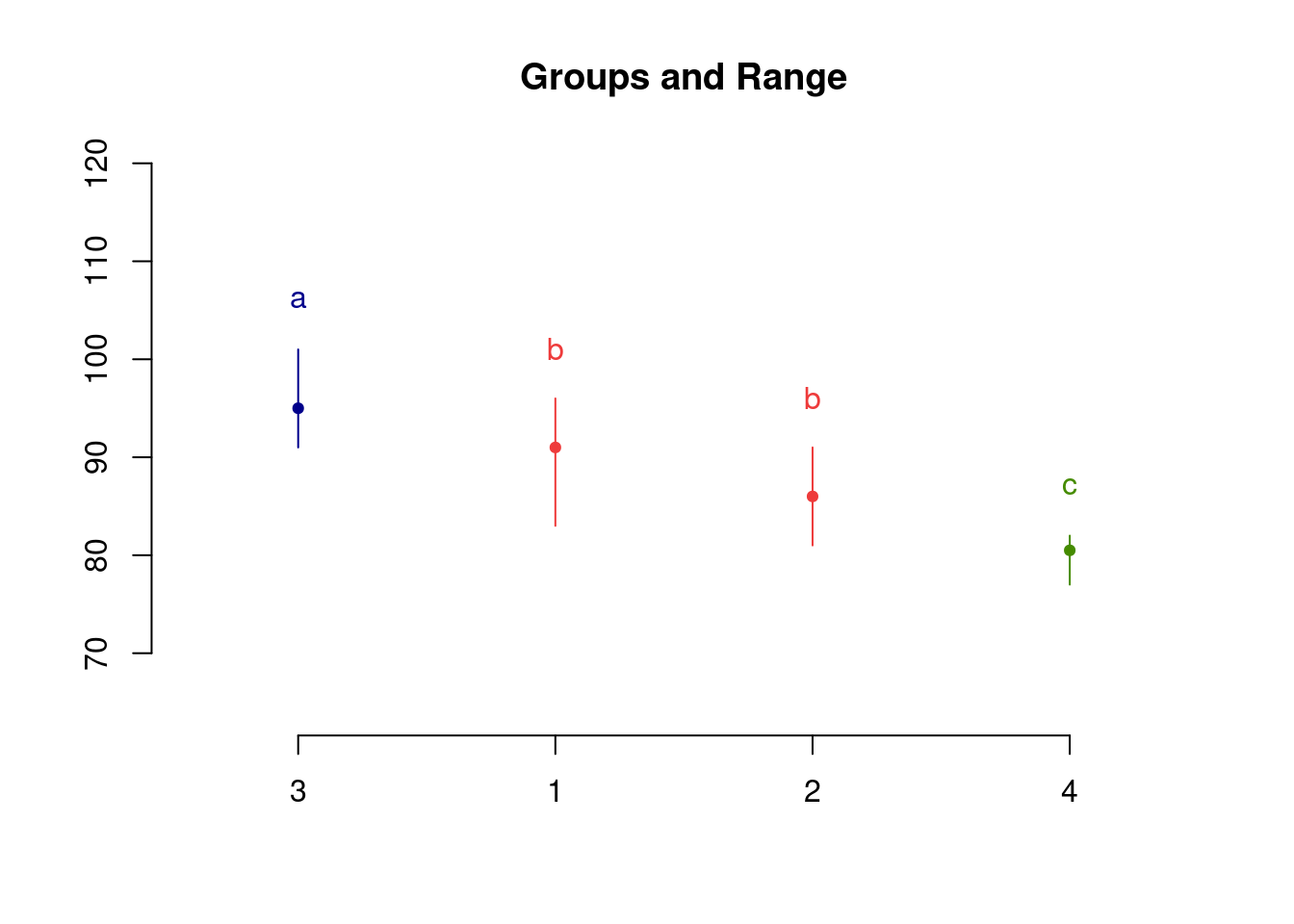
Post Hoc Analysis
Groups according to probability of treatment differences and alpha level.
Treatments with the same letter are not significantly different.
corn$observation groups
3 95.0 a
1 91.0 b
2 86.0 b
4 80.5 c
Multiple Comparison
# Visualizationplot(median_test_out)
Cramer’s Contingency Coefficient
Measures row x column association. Similar to a correlation coefficient between two continuous variables.